{kind=link}
目前分布式大数据应用广泛采用内存计算模型,其中大部分没有全局共享状态,适用于MapReduce和RDD这些通用模型,而另一类应用例如深度学习需要共享全局可变状态。在每个节点计算过程中,有大量的细粒度对全局状态的读写。这类应用其中一些也可以转化为MapReduce和RDD模型来做,但是存在大量的通信等待时间。 本次课程设计,借鉴了Piccolo,Spark,Parameter Server的设计思想,以支持这类有全局共享状态的大数据应用。
充分利用数据本地性,每个节点只计算放在本地内存数据库中的数据
读写数据时预先聚合,为了减少通信开销,在远程读写的时候,可以把请求数据进行预先聚合
本地读和远程写,考虑到大部分深度学习应用的特点,使用了本地读和写远程数据库的策略
非共享数据cache到本地内存。图结构虽然也存储在parameter server中,为了减少通信开销,可以缓存到worker的本地内存中。
为了减少通信代价,parameter server可以支持user-defined functions on server(调试中)
实现的parameter server接口简单,包括set,get,Add
实现了一个迭代的BSP内存计算模型
暂无
使用了静态的Consistent Hash 算法,把数据划分到多个节点上
目前只支持BSP模型
该系统包括了parameter server和内存计算框架,两者之间完全独立。JobMaster负责分配任务,管理同步,故障恢复管理;Worker负责计算和对数据库的读写
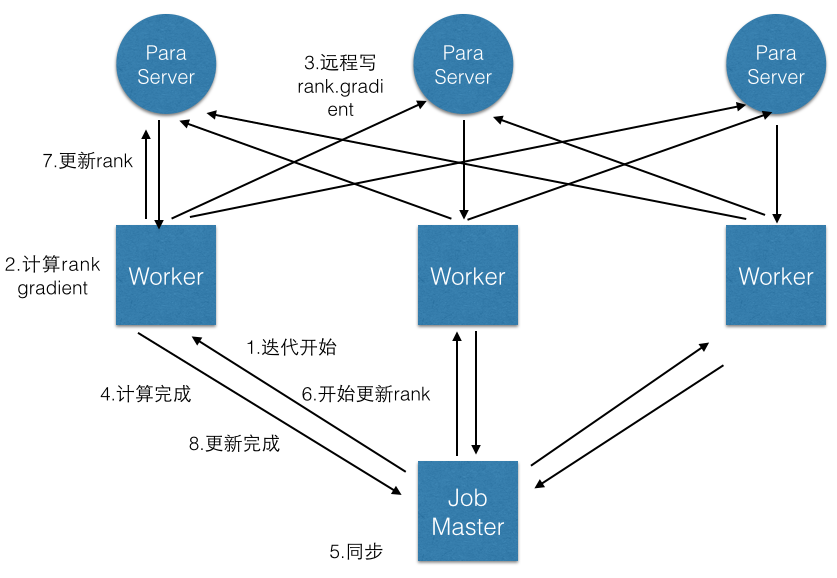
本系统非常仔细地分析了性能瓶颈,并实现了多种策略来优化性能。(参见design goals)。然而为了能在短时间内完成,本系统使用go语言写成,经测试发现性能不好,一方面是go自身的问题,也有e可能是我刚学习go经验不足,用法不对。下一步打算还是用c/c++来重写。
本系统运行的集群包括了两个节点:mac本地系统和一个debian 7 虚拟机。
web-stanford.txt 32.9MB
Nodes: 281903 Edges: 2312497
一次迭代需要63秒
facebook.txt 854KB Nodes: 1947 50次迭代需要236秒
性能差的原因主要在网络通信速度上,经测试发现Go语言的通信库性能非常差,尤其是在mac电脑上。socket传输速度竟然只有350kb/s。经测试,go语言在linux下的网络性能还不错,但整个系统还没有在linux物理机集群上进行测试。 下一步打算用c/c++重写,然后再做详细的性能分析。