nodata用于检测监控数据的上报异常。nodata和实时报警judge模块协同工作,过程为: 配置了nodata的采集项超时未上报数据,nodata生成一条默认的模拟数据;用户配置相应的报警策略,收到mock数据就产生报警。采集项上报异常检测,作为judge模块的一个必要补充,能够使judge的实时报警功能更加可靠、完善。
nodata只处理如下的用户需求,
- 监测"特征采集项"的上报异常
- 监测少量的、十分重要的采集项的上报异常
这里的特征采集项,指的是,能够表征某一监控采集服务数据上报情况的单个采集项。例如,falcon-agent的agent.alive指标就是一个特征采集项,它能够说明agent是否正常存活,进而能够说明通过agent上报的监控数据是否正常。
nodata所谓的异常,限定为 用户数据采集服务异常、falcon数据上报链路异常等,主要场景描述如下。nodata提供了阻塞功能,防止网络故障、falcon服务故障等导致的大面积误报警。
用户数据采集服务异常
- 用户数据采集服务,异常终止
- 用户数据采集服务,与falcon数据收集器之间的通信链路异常,使得数据无法上报
- 用户数据采集服务,上报的数据格式错误
falcon数据上报链路异常
- agent异常,无法接收用户的数据推送、无法主动采集监控数据
- agent与数据转发transfer之间通信异常
从系统边界的描述可知,nodata只是为少数重要的采集指标而设计的。nodata处理的采集项的数量,不应该多于judge的十分之一,nodata的滥用将会给falcon的运维管理带来麻烦。
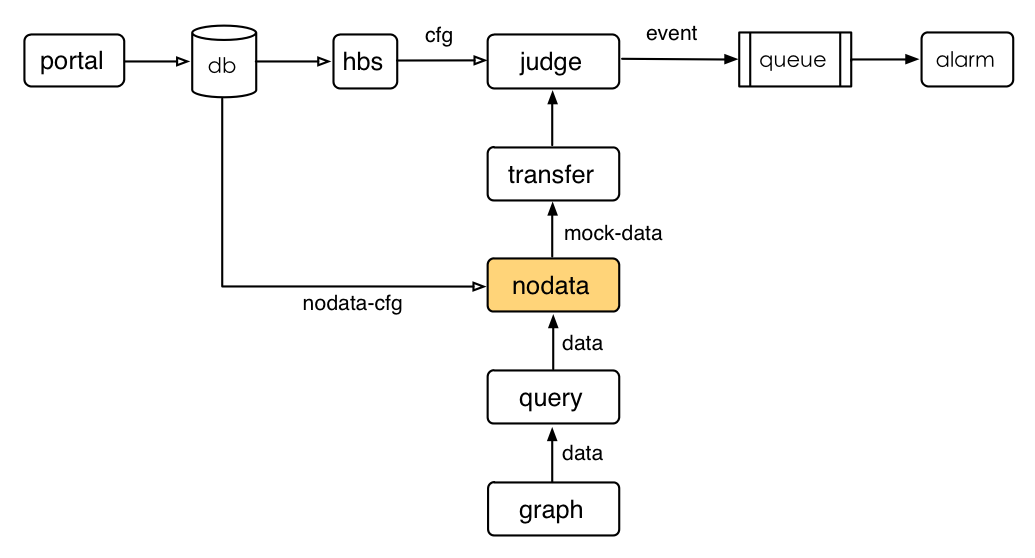
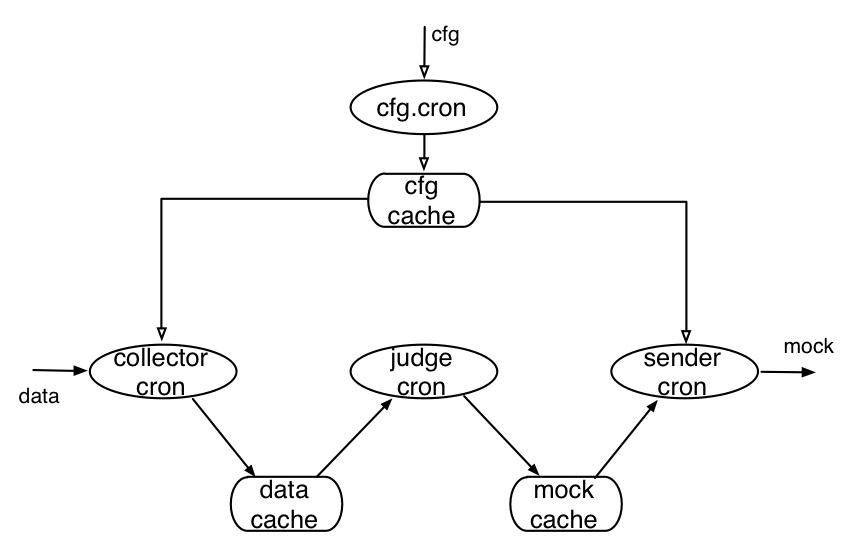
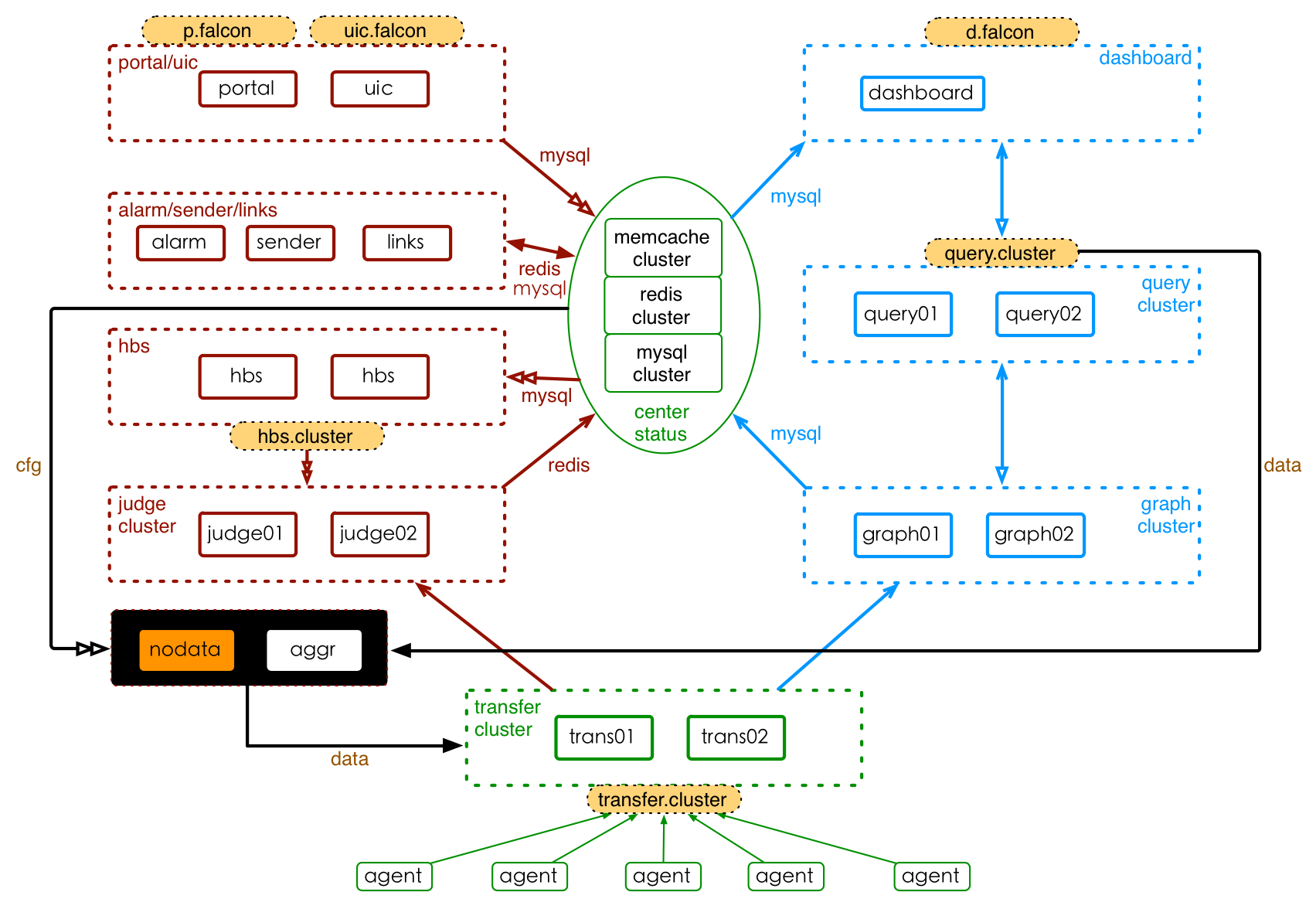
这一节是写给Open-Falcon老用户的,新用户请忽略本小节、直接跳到源码编译部分即可。如果你已经使用Open-Falcon有一段时间,本次只是新增加一个nodata服务,那么你需要依次完成如下工作:
- 确保已经建立mysql数据表falcon_portal.mockcfg。其中,falcon_portal为portal组件的mysql数据库,mockcfg为存放nodata配置的数据表。mockcfg的建表语句,见这里。
- 确保已经更新了portal组件。portal组件中,新增了对nodata配置的UI支持。
- 安装nodata后端服务。即本文的后续部分。
# update common lib
cd $GOPATH/src/github.com/open-falcon/common
git pull
# compile nodata
cd $GOPATH/src/github.com/open-falcon/nodata
go get ./...
./control build
./control pack最后一步会pack出一个tar.gz的安装包,拿着这个包去部署服务即可。
服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
# 修改配置, 配置项含义见下文
mv cfg.example.json cfg.json
vim cfg.json
# 启动服务
./control start
# 校验服务,这里假定服务开启了6090的http监听端口。检验结果为ok表明服务正常启动。
curl -s "127.0.0.1:6090/health"
...
# 停止服务
./control stop
服务启动后,可以通过日志查看服务的运行状态,日志文件地址为./var/app.log。可以通过调试脚本./scripts/debug查看服务器的内部状态数据,如 运行 bash ./scripts/debug 可以得到服务器内部状态的统计信息。
配置文件默认为./cfg.json。默认情况下,安装包会有一个cfg.example.json的配置文件示例。各配置项的含义,如下
## Configuration
{
"debug": true,
"http": {
"enabled": true,
"listen": "0.0.0.0:6090" #nodata的http服务监听地址
},
"query":{ #query组件相关的配置
"connectTimeout": 5000, #查询数据时http连接超时时间,单位ms
"requestTimeout": 30000, #查询数据时http请求处理超时时间,单位ms
"queryAddr": "127.0.0.1:9966" #query组件的http监听地址,一般形如"domain.query.service:9966"
},
"config": { #配置信息
"enabled": true,
"dsn": "root:passwd@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true&wait_timeout=604800", #portal的数据库连接信息,默认数据库为falcon_portal
"maxIdle": 4 #mysql连接池空闲连接数
},
"collector":{ #nodata数据采集相关的配置
"enabled": true,
"batch": 200, #一次数据采集的条数,建议使用默认值
"concurrent": 10 #采集并发度,建议使用默认值
},
"sender":{ #nodata发送mock数据相关的配置
"enabled": true,
"connectTimeout": 5000, #发送数据时http连接超时时间,单位ms
"requestTimeout": 30000, #发送数据时http请求超时时间,单位ms
"transferAddr": "127.0.0.1:6060", #transfer的http监听地址,一般形如"domain.transfer.service:6060"
"batch": 500, #发送数据时,每包数据包含的监控数据条数
"block": { #nodata阻塞设置
"enabled": false, #是否开启阻塞功能.默认不开启此功能
"threshold": 32 #触发nodata阻塞操作的阈值上限.当配置了nodata的数据项,数据上报中断的百分比,大于此阈值上限时,nodata阻塞mock数据的发送
}
}
}
出现以下情况时,nodata不应该引发大面积的报警:
- 由于核心网络故障,导致大部分的采集项上报异常
- 由于falcon自身服务故障,导致大量的采集项上报异常
nodata采用"阈值检测"方法,简答的解决上述误报问题。nodata服务启动时,我们会为它配置一个阻塞阈值,nodata服务实时计算当前处于接收超时状态的监控数据项的百分比(简称异常百分比),然后这个用异常百分比与预先配置的阻塞阈值进行比较。如果异常百分比大于阻塞阈值,nodata服务就会停止发送mock数据;反之,如果异常百分比不大于阻塞阈值,nodata服务则正常发送mock数据。
我们举一个例子来进行说明。假设,我们配置的阻塞阈值为20,系统当前有1000个监控指标项配置了nodata报警。某一段时间,由于IDC核心网络故障,导致300个监控指标无法顺利push到falcon。nodata服务检测到,监控项异常百分比为(300/1000)*100 = 30%,这个取值大于我们预先设置的阈值20%,因此nodata服务停止发送mock数据、直到异常百分比再次降低至不大于20%。
阻塞阈值,可以通过nodata配置文件选项sender.block.threshold来设置,用户可以手动更改配置文件来更新这个阻塞阈值。nodata可以通过Gauss过滤、动态拟合出这个阻塞阈值,这种方式适合于数据上报较稳定的场合,详情可咨询Open-Falcon开发者团队。
处于阻塞期间,所有的数据上报异常将会被忽略,有可能错过一些真实的异常、导致漏报。误报和漏报之间的权衡,需要用户酌情选择是否开启阻塞功能、如何设置阻塞阈值。
使用Nodata,需要进行两个配置: Nodata配置 和 策略配置。下面,我们以一个例子,讲述如何使用Nodata提供的服务。
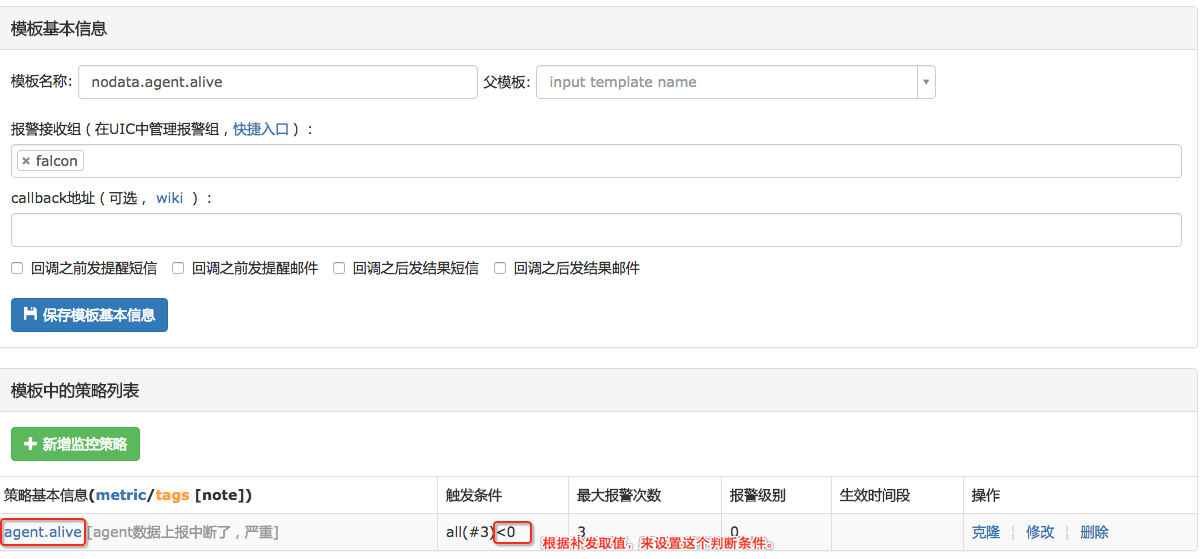
当机器分组cop.xiaomi_owt.inf_pdl.falcon_service.task下的所有机器,其采集指标 agent.alive 上报中断时,通知用户。
进入Nodata配置主页,点击右上角的添加按钮,添加nodata配置。
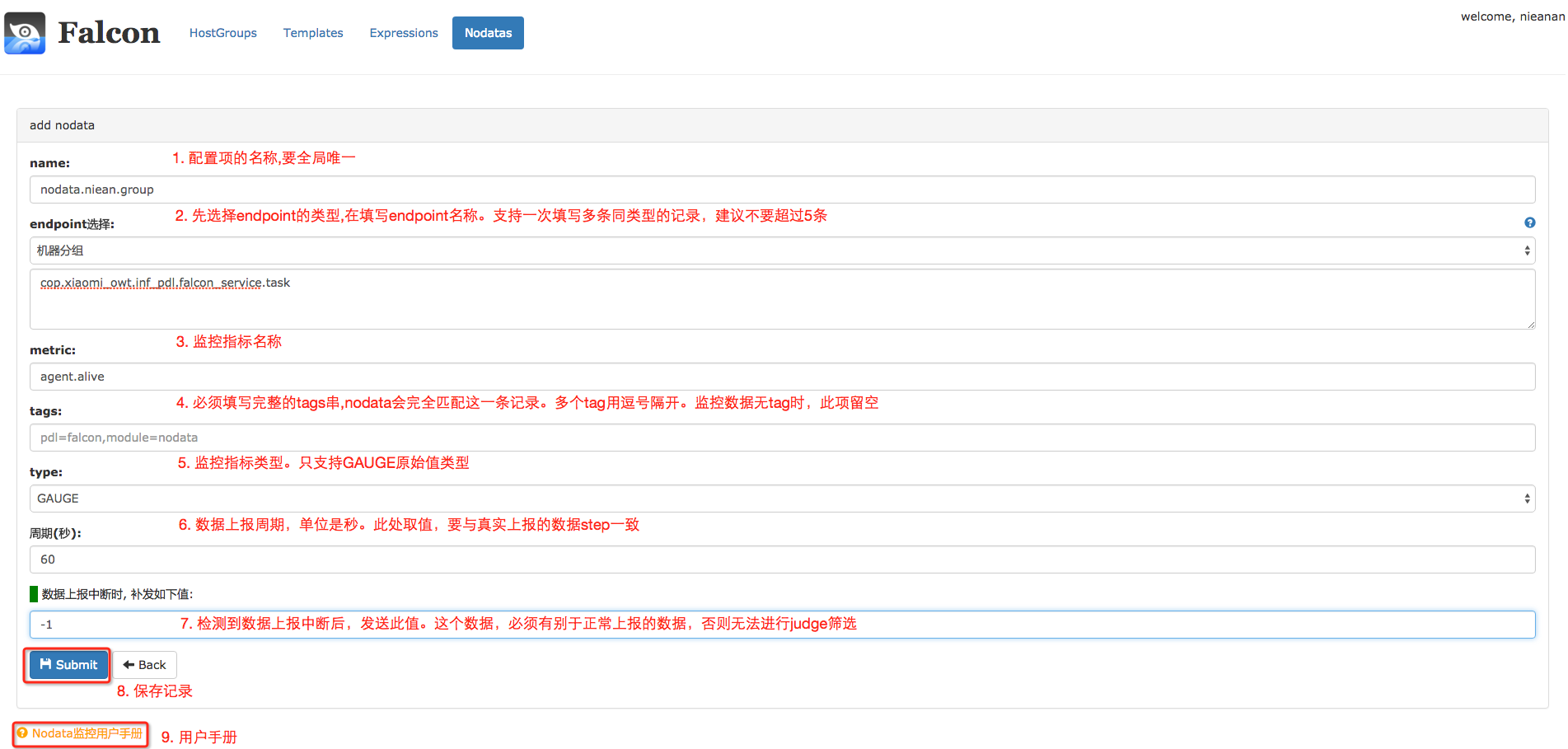
进行完上述配置后,分组cop.xiaomi_owt.inf_pdl.falcon_service.task下的所有机器,其采集项 agent.alive上报中断后,nodata服务就会补发一个取值为 -1.0、agent.alive的监控数据给监控系统。
配置了Nodata后,如果有数据上报中断的情况,Nodata配置中的默认值就会被上报。我们可以针对这个默认值,设置报警;只要收到了默认值,就认为发生了数据上报的中断(如果你设置的默认值,可能与正常上报的数据相等,那么请修改你的Nodata配置、使默认值有别于正常值)。将此策略,绑定到分组cop.xiaomi_owt.inf_pdl.falcon_service.task即可。
- 配置名称name,要全局唯一。这是为了方便Nodata配置的管理。
- 监控实例endpoint, 可以是机器分组、机器名或者其他 这三种类型,只能选择其中的一种。同一类型,支持多个记录,但建议不超过5个。选择机器分组时,系统会帮忙展开成具体机器名,支持动态生效。监控实体不是机器名时,只能选择“其他”类型。
- 监控指标metric。
- 数据标签tags,多个tag要用逗号隔开。必须填写完整的tags串,因为nodata会按照此tags串,去完全匹配、筛选监控数指标项。
- 数据类型type,只支持原始值类型GAUGE。因为,nodata只应该监控 "特征指标"(如agent.alive),"特征指标"都是GAUGE类型的。
- 采集周期step,单位是秒。必须填写 完整&真实step。该字段不完整 或者 不真实,将会导致nodata监控的误报、漏报。
- 补发值default,必须有别于上报的真实数据。比如,
cpu.idle的取值范围是[0,100],那么它的nodata默认取值 只能取小于0或者大于100的值。否则,会发生误报、漏报。